Algorithm Interview
What you need to know
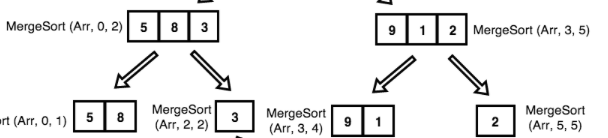
My contract expired with Apple. I worked for them for three years and worked for two different teams in AIML. My experience with Apple was mostly pleasant. Not like the horror stories you read on Reddit or glassdoor.com. I truly had a top-notch experience and I'm eligible for rehire after 6 months.
Converting to a full-time employee is not always a straightforward experience for contractors. They still contact you externally and you interview with 3 to 4 different people. The first interview is usually a social-cultural interview, followed by one or two technical interviews that involve a live coding session to solve a fancy algorithm. The last interview, possibly the third or 4th interview, may or may not be live coding session. It's really a design interview with a possible digital whiteboard.
If you tackle these interviews through a recruiting house, you will get feedback, which is nice. If you apply directly, you will not. A few things to note about Apple are that they plod slowly. It could take two weeks for a simple email reply about the days and times they could interview you, followed by another two-week response for an actual interview. And weeks for a decision. The entire process can be 3 months and you might have to wait an additional month for a start date.
Some of these technical questions can be very difficult. It really depends on the algorithm. I can safely say I solved over 75% of the questions and showed that I can actually code. At least, that is what they reported to my recruiter.
This is one of those situations where you cannot feel offended. As a contractor, I had access to Apple directory and had the luxury to look up the manager and teams internal GitHub repo and really see where I stood in the organization regarding “git commits” and contributions I made compared to the persons who interviewed me. Most of the time, my contributions exceeded those that I interviewed with by a factor of 3. They considered me a workhorse. Dare I say contractors push more code than employees, sometimes at least? This may or may not be a good metric to follow. Quality commits are better. But if you look closely you know who does the most work on the team.
Age could be a contributing factor. I'm not talking about the discrimination of age. I'm talking about the fact that old people can push a lot of code because they have been doing it for a long time.
Do we have age, race, sex discrimination in the workplace? Everyone says no and the laws say no. The reality might be different. Without touching too deeply on the subject. Attractive people lean towards attractive candidates, the same goes for those that are socially competent. Socially competent people have the upper hand. Therefore, you must shine on the interview process. You need to practice rhetoric. Strive for smooth responses in the midsts of hidden anxiety. Look clean and smile. The entire process is exhausting. You really have to act and this is a performance art. This is your demo. Mind you, we are not salespeople. We are programmers, deep in thought, lost in code, and our creativity can't exactly be measured in traditional ways.
Now for the dirty secrets of algorithms.
I have never used a linked list in 25 years. I can count how many times I have used a recursion in a professional capacity. Since I primarily use Python, I can assure you I never use a sorting algorithm when “sort()” or “sorted()” function is so readily available. So what does this leave you with? Probably with the knowledge of data structures, deques, queues, stacks, trees, graphs and searching algorithms. Honestly, it’s hard to remember when you are encouraged to perform.
As much as I love python and can sing its praise. The insatiable benefactors, the beautiful and rich set of libraries and tools so readily available. So extremely well documented. The fact of the matter. PYTHON MAKES YOU A LAZY PROGRAMMER. If I created anger and dissension among the ranks, good!. A multi-paradigm feature doesn't make for a great language. Oh sure, you can build things quickly, dare I say, prototype faster than in any other language.
Duck typing, and or weakly dynamic typing, are one of the many examples that a script programmer commonly abuses. The rest being scope, namespace, GIL concurrency and or (not real) threading, leaky encapsulation because of bad class abstractions. I'm sorry the list goes on and it further detracts from the original title of this article. Algorithm Interviews. I bring this up because I have spent my career cleaning up poorly written scripts by "script" programmers with arduously long peer reviews for clean, optimal written code. This paradigm is the reason for so many style guides such as PEP8, or doc string types such as (ReStructured text, epydoc, google doc, epytex). Or drop all of this stuff and make everything statically typed with 'typing' and 'type hints' and the mess persists when you mix and break the rules because it's hard to accommodate all of this when performing unit testing as well. Let’s get back to what you need to know that I’m sure you might have forgotten.
The mastery of iteration over lists, dicts, and tuples, strings, is a straightforward task. It's obvious they will sometimes ask you simple questions about the differences. You never know how it starts out. Sometimes it begins with a few statements about “xyz” or a full-blown exercise. Yes, I have been asked the following.
Find the median
bazinga = [1, 2, 3, 4, 5]
med = len(bazinga) // 2
print(bazinga[med])
Even as simple as printing, only even integers
foo = []
for i in range(101):
if i % 2 == 0:
foo.append(i)
print(foo)
[0, 2, 4, 6, 8, 10,...]
The problem with these types of interviews is you never know the direction they go. I had an interviewer ask me to sort a list:
my_list = [1, 7, 3, 2]
print(sorted(my_list))
He then asked about the complexity. Mind you, he was not a python programmer. I mentioned in this case its constant 0(1). But only on this block or this instance. I couldn't remember which algorithm python actually uses, but that it was a matter of frequencies. I mentioned this because previously I was on hackerrank.com performing an efficient sort using frequencies. In the long run its more of a stable sort, but not the most efficient. Please keep in mind that the conversation at the time was still enjoyable and the beginning of a new rabbit hole. I mentioned I'm not sure which algorithm python uses for sort. Come to find out it's a time-sort hybrid of merge sort and insert sort.
The interviewer asked in such a way to stimulate thought and lead to performing a sorting algorithm manually. It’s lucky I had a few sorting algorithms in my head. I think you kind of have to, to a certain extent. It’s also a splendid exercise messing with lists, as I will get into later.
Here is my rudimentary insert sort
my_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
for i in range(1, len(my_list)):
cur = my_list[i]
pos = i
while pos > 0 and my_list[pos-1] > cur:
my_list[pos] = my_list[pos-1]
pos -= 1
my_list[pos] = cur
print(my_list)
The complexity is O(n2). Just increase the factor for each iterative. That's kind of how it works. Big 0 notation is a combination of time and space complexity. I will not delve deep into this because there is a plethora of information available on this topic. But let's be honest. We need to know the basics and the rest of the time everyone uses google or wiki to get the best answer.
Clearly constant is best, but this was easy to remember logically. But he wanted to improve on this scenario. It was a direction I didn't want to go down, but I knew this would happen. Maybe it’s the alignment of the stars or some sort of Higgs boson particle experiment where particles are changing because of the scientists inspection at the time of collision. Am I manifesting the outcome? Did I purposely lead myself into a recursion? He wanted O(n log(n))
As luck would have it, I had a Quicksort in my brain as well for backup. So perhaps this is what you need to do as well. How many sorts can you memorize? Do you have bubble sort, insert, and merge sort memorized?
def my_quick(data):
large = []
small = []
size = len(data)
if size <= 1:
return data
else:
move = data.pop()
for item in data:
if item > move:
large.append(item)
else:
small.append(item)
return my_quick(large) + [move] + my_quick(small)
print(my_quick([54, 26, 93, 17, 77, 31, 44, 55, 20]))
The thing here is that you have to make these algorithms yours. Here, I probably should have chosen better names such as upper and lower for arrays. I'm infamous for picking awful names. Small, large, length, whatever. As long as it’s not a keyword. But it could make for confusion. For the season developer, you might notice a problem here. My list is backwards. It was backwards when I ran it. But I'm such a syntactical wiz on python I simply changed my print statement as follows [::-1]:
print(my_quick([54, 26, 93, 17, 77, 31, 44, 55, 20])[::-1])
Clearly, this was a giggle moment. Yes, we both laughed together. It's also a reflection of my experience. More so on time management. When you have pressure from upper management to get the job done now! The correct answer is swap out 'large' for 'small' on the return statement.
We talked about other things such as benchmarks, time() and size. I imported 'timeit' and introduced it. We talked about gotcha's, repeating numbers, random number generation and so forth.
It was all enough to go to the next round. But to make this more well rounded here are other examples.
Isolate duplicate data
input = [
/blah/dir1 file1(asdf) file2(qwer)
/blah/dir2/file3(qwer)
blah/dir3 file4(asdf) file5(jkl)
]
output = [
[
blah/dir1/file(asdf)
blah/dir3/file4(asdf)
],
[
blah/dir1/file2(qwer)
blah/dir2/file3(qwer)
],
[
blah/dir3/file5(jkl)
]
]
Not a terribly troublesome question, but can catch you off guard when you have multiple ways to solve this. Should you perform some matching? Would you like to group this? What structure will you hold this in? The premise was that the contents of the files would contain data such as “qwer”, “jkl”, “asdf”. But it was simulated, so I had to create a parser to split that into a table, but I would track all the files in a dictionary. I ended up with a long ugly solution and it was not my best work. Too large to post here. You can find my solution in my personal (GitHub/ thecount12)
This was an Apple question and I would argue that while my brute force method wasn't the best, does it not show an ability to code? What is the point here? I saw his commits, and he did not impress me. I pushed more code in two months than he did in a year. This was a few months ago and caused the spiral of studying for these live code interviews.
Here is another apple question target sum algorithm. Solution below is an elegant one.
class Solve:
def two_sum(self, num_ar, target):
l = []
d = {}
for i, n in enumerate(num_ar):
if target-n in d:
l.append(d[target-n])
l.append(i)
break
d[n] = i
return l
s = Solve()
print(s.two_sum([2,7,11,15], 9)) # result [0, 1]
However, my brute force method was twice as long and not perfect !!!in the long run. I'm not sure what the interviewer was expecting, and they deviated beyond the algorithm by finding multiple sums for the same target value and not repeating the results or a mirrored result output. I get the nature of the algorithm and the goal of the interviewer. But some instances required patience and consideration. You are trying to cram a lot by solving a puzzle in 15 to 20 minutes. These interviews almost always have three questions. Is the purpose of the interview to simply just be brilliant. Oh, this can be argued all day!!!
In real life, when you are asked to search for unique information, that is only the beginning of a request. Which is why I lean towards dictionaries. When asked to find duplicates. I can't help but use a dictionary because with one flip or simple change. I can show “dups”, “uniques”, “first”, “last”, “max”, “min” . Because in the real world, more is always better. Once my data is a dictionary, I become the list comprehension master.
Frustration can grow into a monster. I seriously had to take two weeks off and go back over algorithms books and “geeksforgeeks”. But it wasn't just that. My code capabilities are not quick. On hackerrank.com, I would do three puzzles followed by the mock timed test and I noticed I would barely make it to the last second. I was just slow. I was making a lot of mistakes, indents, spelling, etc... The same anxiety when coding live. In real life I use log or logger. But on these tests, I was using print statements everywhere as I brute force my way through it, only to end up quickly commenting out my print statements before the test time expired. I love “fstrings” in python. I labeled all my prints statements with a “todo” at the end so I can quickly un-comment everything.
for i in array:
print(f"item: {i}") # todo remove me
if i not in my_dict.keys():
my_dict['car'] = i
Recommendations
Make sure you throw everything into a function or method. Tell the interviewer what you are doing. "Let me make sure my iteration is working before I continue, or let me get the logic out of the way before I return the results. "
Exposure is the key. I searched for every puzzle, Valid mountain, stair-step, Cups, House-robber, target-sum, 4-sum, recursive digit sum, grid challenge, matrix flip. You need to solve these puzzles by yourself, then look at other people’s solutions. Patterns become a key and overtime you will eventually leverage a hand full of patterns to solve most of the problems. The more you practice, the faster you get. Repetition is the key if you want a stellar interview.
My routine was to get up in the morning and hit 3 problems on hackerrank.com, three problems on glider and take a mock test at the end.
Strangely, I made better progress when I picked an unfamiliar language. I would always choose python for an interview test because everyone knows python now. But on my personal time I transitioned to Golang and discovered a lot of weaknesses.
Getting a count so I can search for duplicates in python here
m_dict = {}
for i in self.data:
if i not in m_dict.keys():
m_dict[i] = 1
else:
m_dict[i] += 1
print(m_dict)
I'm building a dict and incrementing the value if a duplicate shows up.
res = {k:v for k,v in m_dict.items() if v == 1}
But in Golang I could not use this logic at all. Maps were different. The thinking is different.
package main
import "fmt"
func main() {
dataList := []int{1, 2, 3, 3, 4, 5}
myMap := make(map[int]int)
for i := 0; i < len(dataList); i++ {
fmt.Println(dataList[i])
item, found := myMap[dataList[i]]
if !found {
fmt.Println("its not int the list lets add")
myMap[dataList[i]] = 1
} else {
fmt.Println("in list lets increment: ", item)
myMap[dataList[i]] += 1
}
}
fmt.Println(myMap)
}
The experience of switching to an unfamiliar language will prove invaluable and definitely push your skills. Surprisingly, I started testing in 'C'. I had to push myself just far enough out of my comfort zone that I was manually doing everything instead of relying on a rich set of libraries or builtin’s. K&R sort still works. That old book is still gold today, (quick) qsort, and binary search. Before bool was even added to Ansi “C” it was just a 1 or 0 flag. It really brings you back full circle but also reminds you how lazy of a programmer you have become. The industry made us this way with front-end, API’s and full-stack which is really AKA for (do everything LAMP but in the cloud and do DevOps for it also). It’s all object level stuff now and almost no primitives. Okay let me retract that. I can assure you in python I’m not thinking about heap or stack. Are too many things abstracted from us? I’m trying to stimulate additional thought. These interviews can be difficult and sadly they don’t want to pay you the FAANG salary rate. But FAANG wants old school data structure knowledge and algorithmic experience. Of course they do. It’s where brilliant people go to die. They go to google. Things need to change and maybe change is here.
Does all of this make you a brilliant software developer? NO NO NO. Some people just can’t code fast enough in such a short period and really show experience. Personally, that is a sloppy metric for potential employment and I'm sure they are turning suitable candidates away.
Other things need to be considered, beyond live code interviews, such as references, and example work such as your own personal git repo. Sure, I recognize most of your contributions went to private enterprise repositories, but surely you have some side work somewhere on display.
Lastly on your algorithmic journey beyond daily practice. Realize it’s just a number game. You will fail some of these interviews and I'm sure you will learn a lot from the experience. The hard interviews are the ones where you pass but still don't get hired. These companies see a lot of candidates. They pick what they feel is the correct best match.
Yes, you are probably right. They made the wrong choice because you are the best candidate. So hang in there.
To post a comment you need to login first.